This Website
This website that you are looking at is powered by Ruby on Rails and React/Redux admin page.
There's a simple WYSIWYG, image uploader and tagging system.
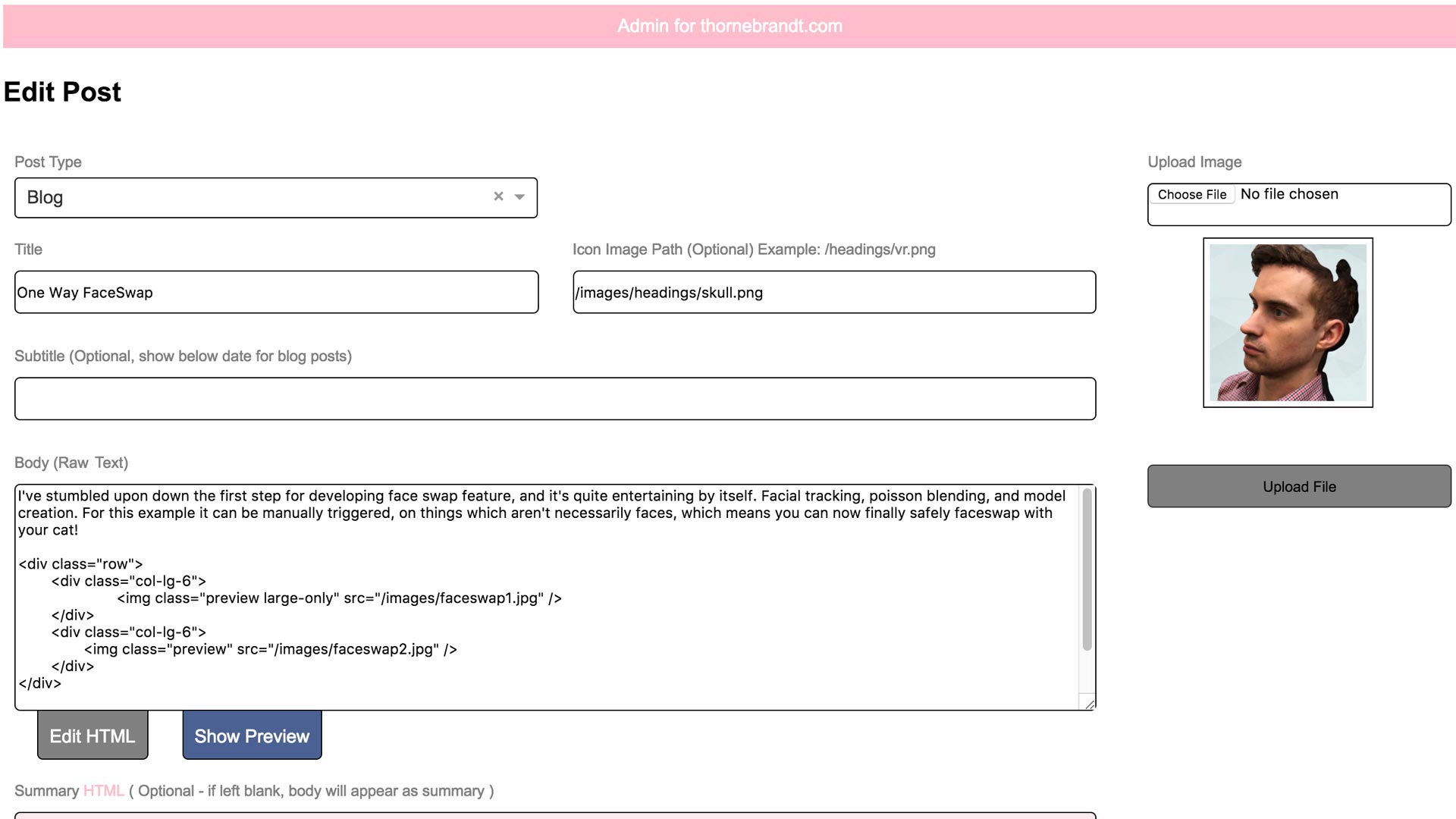
Rails is traditional a strong choice for multi-page applications ( such as a blog. ) and I specifically chose it because of the ease of server side rendering for SEO. ActiveRecord for the backend is pretty simple to work with. I chose Redux for the admin precisely because I didn't know it and this was a great project to experiment creating a WYSIWYG from scratch using Test-Driven Development.
Here are the tests for the WYSIWYG. This was one of my first exercises of TDD for a larger project. While this isn't the cleanest WYSWIG in the world, and makes a lot of opinions ( for example, it adds grid tags around image tags ) , it serves my purpose for quickly creating content for a blog post. These tests were written first to fail, and then I wrote some regex to make them pass.
import * as helpers from '../Posts/helpers/';
describe('textToHTML', () => {
it('parses html', () => {
const body = 'hey';
const bodyHTML = '<p>\nhey\n</p>';
expect(helpers.textToHTML(body)).toEqual(bodyHTML);
});
it('removes extraneous paragraphs', () => {
const body = ''
const bodyHTML = '';
expect(helpers.textToHTML(body)).toEqual(bodyHTML);
});
it('parses html line breaks', () => {
const body = 'firstLine\nsecondLine\nthirdLine';
const bodyHTML = '<p>\nfirstLine\n<br/>\nsecondLine\n<br/>\nthirdLine\n</p>';
expect(helpers.textToHTML(body)).toEqual(bodyHTML);
});
it('converts <p> tags to line breaks', () => {
const bodyHTML = '<p>\nP tag here\n</p>';
const body = 'P tag here\n';
expect(helpers.HTMLToText(bodyHTML)).toEqual(body);
});
it('converts <img> markup to img[]', () => {
const body = 'img[images/fakeImage.jpg]';
const bodyHTML = '\n<div class="row">\n' +
'<div class="col-lg-12">\n' +
'<img class="preview" src="images/fakeImage.jpg"/>\n' +
'</div>\n' +
'</div>\n';
expect(helpers.HTMLToText(bodyHTML)).toEqual(body);
});
it('converts double <img> markup to imgs[]', () => {
const body = 'img[images/fakeImage.jpg,images/fakeImage2.jpg]';
const bodyHTML = '\n<div class="row">\n' +
'<div class="col-lg-6">\n' +
'<img class="preview" src="images/fakeImage.jpg"/>\n' +
'</div>\n' +
'<div class="col-lg-6">\n' +
'<img class="preview" src="images/fakeImage2.jpg"/>\n' +
'</div>\n' +
'</div>\n';
expect(helpers.HTMLToText(bodyHTML)).toEqual(body);
});
it('converts double <img> markup to imgs[]', () => {
const body = 'img[images/fakeImage.jpg,images/fakeImage2.jpg]';
const bodyHTML = '\n<div class="row">\n' +
'<div class="col-lg-6">\n' +
'<img class="preview" src="images/fakeImage.jpg"/>\n' +
'</div>\n' +
'<div class="col-lg-6">\n' +
'<img class="preview" src="images/fakeImage2.jpg"/>\n' +
'</div>\n' +
'</div>\n';
expect(helpers.HTMLToText(bodyHTML)).toEqual(body);
});
it('converts <video> markup to vid[]', () => {
const body = 'vid[fakeVideo]';
const bodyHTML = [
'<video controls poster="fakePoster.png">\n',
'<source src="/videos/fakeVideo.webm" type="video/webm">\n',
'<source src="/videos/fakeVideo.ogv" type="video/ogg">\n',
'<source src="/videos/fakeVideo.mp4" type="video/mp4">\n',
'</video>'
].join('');
expect(helpers.HTMLToText(bodyHTML)).toEqual(body);
});
it('converts multiple <p> tags to line breaks', () => {
const bodyHTML = '<p>P tag here</p><p>Second Paragraph</p>';
const body = 'P tag here\n\nSecond Paragraph\n';
expect(helpers.HTMLToText(bodyHTML)).toEqual(body);
});
it('converts a <p> tag that include a class with line breaks', () => {
const bodyHTML = '<p class="hey">tag with class</p>';
const body = 'tag with class\n';
expect(helpers.HTMLToText(bodyHTML)).toEqual(body);
});
it('converts <br> tags with line break', () => {
const bodyHTML = '<p>FirstLine<br/>SecondLine</p>';
const body = 'FirstLine\nSecondLine\n';
expect(helpers.HTMLToText(bodyHTML)).toEqual(body);
});
it('parses html double line breaks as paragraphs', () => {
const body = 'firstParagraph\n\nsecondParagraph';
const bodyHTML = '<p>\nfirstParagraph\n</p>\n<p>\nsecondParagraph\n</p>';
expect(helpers.textToHTML(body)).toEqual(bodyHTML);
});
it('determines an image', () => {
expect(helpers.isImage("image.jpg")).toBe(true);
expect(helpers.isImage("image.png")).toBe(true);
});
it('determines a video', () => {
expect(helpers.isVideo("image.ogv")).toBe(true);
expect(helpers.isVideo("image.mp4")).toBe(true);
});
it('determines if name', () => {
expect(helpers.isName("oneString")).toBe(true);
expect(helpers.isName("o String")).toBe(false);
});
it('doesnt allow invalid images', () => {
expect(helpers.isImage("n.onImagejpg")).toBe(false);
expect(helpers.isImage("i mage.jpg")).toBe(false);
expect(helpers.isImage("image\nnewline.jpg")).toBe(false);
});
it('doesnt allow invalid videos', () => {
expect(helpers.isImage("videomp4")).toBe(false);
expect(helpers.isImage("v ideo.mp4")).toBe(false);
expect(helpers.isImage("vid/coolvid.mp4")).toBe(false);
expect(helpers.isImage("vid\ncoolvid.mp4")).toBe(false);
});
it('parses img tags', () => {
const body = 'img[images/fakeImage.jpg]';
const bodyHTML = '\n<div class="row">\n' +
'<div class="col-lg-12">\n' +
'<img class="preview" src="images/fakeImage.jpg"/>\n' +
'</div>\n' +
'</div>\n';
expect(helpers.textToHTML(body)).toEqual(bodyHTML);
});
it('parses imgs (plural) tags', () => {
const body = 'imgs[images/fakeImage.jpg,images/fakeImage2.jpg]';
const bodyHTML = '\n<div class="row">\n' +
'<div class="col-lg-6">\n' +
'<img class="preview" src="images/fakeImage.jpg"/>\n' +
'</div>\n' +
'<div class="col-lg-6">\n' +
'<img class="preview" src="images/fakeImage2.jpg"/>\n' +
'</div>\n' +
'</div>\n';
expect(helpers.textToHTML(body)).toEqual(bodyHTML);
});
it('parses img tags with text around them', () => {
const body = 'I am going to show an image. img[images/fakeImage.jpg] after image';
const bodyHTML = '<p>\nI am going to show an image. \n</p>\n' +
'<div class="row">\n' +
'<div class="col-lg-12">\n' +
'<img class="preview" src="images/fakeImage.jpg"/>\n' +
'</div>\n' +
'</div>\n' +
'<p>\n'+
' after image\n' +
'</p>';
expect(helpers.textToHTML(body)).toEqual(bodyHTML);
});
it('parses code tags', () => {
const body = '```alert("hello");```'
const bodyHTML = '<p>\n<pre><code>alert("hello");</code></pre>\n</p>';
expect(helpers.textToHTML(body)).toEqual(bodyHTML);
});
it('does not add html line breaks to code tags', () => {
const body = 'line break after this\n```alert("hello");\nalert("goodbye");\nalert("wait");```'
const bodyHTML = '<p>\nline break after this\n<br/>\n<pre><code>alert("hello");\nalert("goodbye");\nalert("wait");</code></pre>\n</p>';
expect(helpers.textToHTML(body)).toEqual(bodyHTML);
});
it('adds less than and greater than to html codes', () => {
const body = '```<p>hello</p>```';
const bodyHTML = '<p>\n<pre><code><p>hello</p></code></pre>\n</p>';
expect(helpers.textToHTML(body)).toEqual(bodyHTML);
});
it('does not parse incomplete image tags', () => {
const body = 'img[images/fakeImage.jpg'
const bodyHTML = '<p>\nimg[images/fakeImage.jpg\n</p>';
expect(helpers.textToHTML(body)).toEqual(bodyHTML);
});
it('strips file extension', () => {
const fileName = 'fakeExtension.mov';
const stripped = 'fakeExtension';
expect(helpers.stripExtension(fileName)).toBe(stripped);
});
it('parses video tags', () => {
const body = 'vid[video]';
const bodyArray = [
'<p>\n<video controls poster="/images/video.png">\n',
'<source src="/videos/video.webm" type="video/webm">\n',
'<source src="/videos/video.ogv" type="video/ogg">\n',
'<source src="/videos/video.mp4" type="video/mp4">\n',
'</video>\n</p>'
];
const bodyHTML = bodyArray.join('');
expect(helpers.textToHTML(body)).toEqual(bodyHTML);
});
});
...and then the actual methods looked like this.
const parseVideos = (body) => {
const reg = /vid\[([^\]]+)\]/g;
const bodyArray = [
'<video controls poster="/images/$1.png">\n',
'<source src="/videos/$1.webm" type="video/webm">\n',
'<source src="/videos/$1.ogv" type="video/ogg">\n',
'<source src="/videos/$1.mp4" type="video/mp4">\n',
'</video>'
];
return body.replace(reg, bodyArray.join(''));
};
It's assuming that I have uploaded three versions of the video for different browsers, as well as an image with the same name. If there's a discrepancy, I can always switch to html mode for fine tuning. Since it's react, it's fairly trivial to display a live preview, so it's a quick scrolldown to see if the post looks correctly.
This complete file is here
There's also some interesting code in the uploaderActions.
export const chooseFile = (target) => dispatch => {
let file, reader;
dispatch(loading(true));
if(target.files.length){
file = target.files[target.files.length - 1];
if(file.type.match(/image.*/)){
if(window.FileReader) {
reader = new FileReader();
reader.addEventListener('load', (e) => {
dispatch(loading(false));
return dispatch(showImagePreview(e.target.result, file));
});
}
} else {
dispatch(loading(false));
return dispatch(showFileSize(file));
}
reader.readAsDataURL(file);
} else {
dispatch(loading(false));
return dispatch(invalidFile);
}
};
export const showImagePreview = (src, file) => {
return ({
type: 'SHOW_IMAGE_PREVIEW',
src,
file
});
};
export const uploadFile = (e, file) => dispatch => {
e.preventDefault();
let fetchFile;
let fd = new FormData();
if(file.type.match(/image.*/)){
fetchFile = fetchImage;
fd.append('image', file);
} else if(file.type.match(/video.*/)) {
fetchFile = fetchVideo;
fd.append('video', file);
} else {
return dispatch(throwError('Didn\'t recognize that file type: ' + file.type));
}
dispatch(loading(true));
return fetchFile(fd)
.then(response => response.json())
.then((json) => {
dispatch(loading(false));
return dispatch(addFile(json));
})
.catch((e) => {
dispatch(loading(false));
const errorString = 'There was a problem with uploading the file\n' + e;
return dispatch(throwError(errorString));
});
};
This will determine the type of file that I want to upload, determine file size, show an image preview ( if it's an image ) , then show the path which is easily copy pasted in to the WYSWIG.